
: Una Guía Paso a Paso para lograr ChatGPT con Contexto")
Los Modelos de Lenguaje de Gran Tamaño (LLM, por sus siglas en inglés), especialmente aquellos del tipo “generativo”, han causado un gran impacto en el mundo. Y la Generación Mejorada por Recuperación (RAG, por sus siglas en inglés) se ha vuelto muy popular como la técnica predominante para que los LLM respondan preguntas basadas en nuestra información personalizada.
Entiendo que hay muchas herramientas en el mercado hoy en día para ayudar a configurar RAG en minutos, pero antes de usar las herramientas sofisticadas que ocultan todos los detalles de implementación, quizás quieras entender qué está pasando realmente bajo la superficie. Y no hay mejor manera de aprender cómo funcionan las cosas que escribir el código uno mismo. Así que, aquí va un paso a paso, con explicaciones detalladas.
Entiendo que hay muchas herramientas en el mercado hoy en día para ayudar a configurar RAG en minutos, pero antes de usar las herramientas sofisticadas que ocultan todos los detalles de implementación, quizás quieras entender qué está pasando realmente bajo la superficie. Y no hay mejor manera de aprender cómo funcionan las cosas que escribir el código uno mismo.
Así que, aquí va un paso a paso, con explicaciones detalladas.
Requisitos:
- Docker (o un entorno de Python con langchain, openai, pandas y numpy)
- Acceso a la API de OpenAI
- Interés en entender cómo funcionan las cosas
Si usas la ruta de Docker, puedes usar este Dockerfile:
Constrúyelo y ejecútalo montando la carpeta local donde escribirás tu código de Python:
docker build . --tag rag
docker run --rm -it -v $(pwd):/src rag bashSi vas a usar Docker, escribe el código en la carpeta fuera de Docker, y ejecuta en la shell del contenedor. Visual Studio Code hace esto muy fácil, pero también se puede hacer manualmente.
Así que, lo primero que necesitarás es configurar tus variables en el entorno. En Linux:
export OPENAI_API_KEY="xxxx"Interactuando con ChatGPT
Perfecto, así que ahora simplemente charlaremos con ChatGPT a través de Python.
Como puedes ver, escribir código para charlar con ChatGPT es extremadamente simple. Pero, en este punto, ChatGPT solo está respondiendo desde su propio conocimiento (miles de millones de documentos de entrenamiento). Para que ChatGPT use nuestra propia base de conocimiento para responder las preguntas necesitamos encontrar una manera de inyectar nuestros datos en esa conversación. Pero no es tan fácil. ChatGPT no puede ser “alimentado” con grandes cantidades de datos, así que necesitamos encontrar los documentos más relevantes por nosotros mismos, y proporcionárselos a ChatGPT como contexto para la pregunta. Y preferiríamos lograrlo sin tener que implementar otro LLM, ni tener que reentrenar o ajustar estos modelos cada vez que nuestros documentos cambien. Déjame mostrarte cómo hacer justo eso.
Incrustaciones y vectores
Para que ChatGPT responda la pregunta basándose en tu contenido, primero necesitas entender un poco sobre las incrustaciones. Una incrustación es una representación vectorial de la semántica de un texto. Es lo que nos permite usar conceptos, herramientas y técnicas matemáticas para manipular y comparar texto. Déjame mostrarte un ejemplo:
Lo primero que notarás es que el contenido de “resultados” es enorme. Es un arreglo muy grande de números de punto flotante que representan el texto. Esos números no son una versión encriptada o codificada del texto, representan el significado semántico del texto en vectores de alta dimensión.
Para intentar entender esto, imaginemos que quiero representar personas con números. Creo que podría hacer esto fácilmente con la edad. Puedo representar a una persona de 2 años con un número 2 y a una de 4 años con un número 4. Dado que solo tenemos una dimensión, podría representarlas con líneas y se vería algo así:
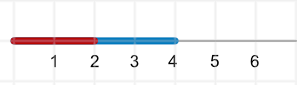
Pero entonces, si quisiera agregar un componente de altura en pies, la representación tendría que agregar una segunda dimensión y se vería así:
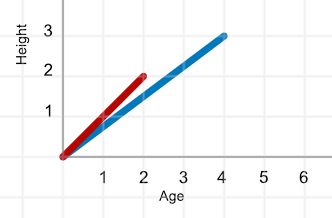
La información ahora tiene dos dimensiones, y aunque podríamos simplemente dibujar un punto en las intersecciones de la edad y la altura, realmente estamos más interesados en ver el vector (recuerda, magnitud y dirección). En este caso, la persona de 2 años está representada por un vector de dos dimensiones:
Las cosas se vuelven un poco más complejas si agrego una tercera dimensión: peso en kilogramos. El vector ahora tiene un valor diferente en cada dimensión, y el gráfico ahora es tridimensional:
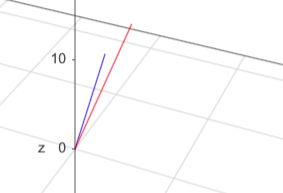
Nota que la dirección para un vector bidimensional estaba representada por el ángulo de la línea, pero ese no es el caso más allá de dos dimensiones. Agregar una cuarta dimensión hace que sea muy difícil dibujar en un sistema bidimensional como nuestras pantallas, y se mueve a un ámbito que es difícil de visualizar, sin embargo, el análisis de la descripción de estas dos personas en cuatro dimensiones diferentes que pueden ser representadas por números es lo que nos permite usar algoritmos y herramientas existentes para manipular estos objetos no numéricos.
Ahora, volviendo a los resultados que obtuvimos de la solicitud para crear una incrustación vectorial de nuestro texto, los Modelos de Lenguaje de Gran Tamaño (LLM) identifican miles de dimensiones contra las cuales se evalúa el texto y devuelven este gran número de coordenadas que describen el texto en un vector de alta dimensión. En el caso del modelo text-embedding-ada-002, devuelve un vector de 1,536 dimensiones.
También, nota que los vectores para ambos textos tienen la misma cantidad de dimensiones, la longitud del texto no afecta la cantidad de dimensiones contra las que ha sido evaluado. Eso es clave, porque hará posible la comparación de los dos vectores, siendo que representan el significado semántico de los textos en las mismas dimensiones.
Similitud de vectores
Ahora que hemos creado incrustaciones con éxito, necesitamos averiguar cómo nos ayudarán a realizar tareas de IA. En primer lugar, notemos que lo que hemos hecho es crear una representación del significado semántico de esos textos usando vectores. En segundo lugar, los vectores son conceptos matemáticos, y tenemos formas matemáticas de tratar con ellos. Por ejemplo,
Nota que comparé dos vectores de dos dimensiones, y que ambos tienen los mismos números, dos y cinco, pero, la similitud entre ellos es solo del 68%.
Incrementemos las dimensiones:
La similitud es aún menor, estos dos vectores definitivamente van en direcciones diferentes. Recuerda que aunque tengamos dos dieces, dos cincos, etc., la comparación es por dimensión, por lo que la función está comparando 1 con 10 en la primera dimensión, 2 con 5 en la segunda, y así sucesivamente. La comparación por dimensión encuentra que estos dos vectores son muy diferentes. El punto se reforzará si usamos números totalmente diferentes en ambos vectores, pero que mantienen una dirección y magnitud similares:
Como puedes ver, estos conjuntos de números completamente diferentes son en realidad 98% similares porque su dirección y magnitud son casi idénticas. Ahora comparemos los valores de los niños de 2 y 4 años:
Wow, más del 99% similares, lo que la función cosine_similarity nos está diciendo es que estos dos vectores representan casi lo mismo. Si lo piensas, ambos vectores representan a un niño en diferentes momentos de su vida, de ahí la similitud. ¿Qué pasa si comparamos el vector de un niño de 2 años con el de un adulto? Bueno, los resultados serán completamente diferentes:
Estos dos individuos son tan diferentes que esta comparación superficial sobre solo cuatro dimensiones los considera estar muy lejos el uno del otro.
Similitud de incrustaciones
Ahora que entendemos mejor cómo se pueden comparar dos vectores, volvamos a los dos vectores que obtuvimos de text-embedding-ada-002 de OpenAI y comparémoslos:
Al comparar vectores de incrustación para similitud de texto, aunque sean tan disímiles como estos, observaremos que, semánticamente, su similitud suele estar por encima del 70%, así que un 72% es bajo.
Entonces, cambiemos los textos por algunos textos similares:
Ok, estos dos textos comparten tres palabras y solo difieren en una, sin embargo, la similitud es solo del 86%. ¿Qué pasa con dos oraciones que básicamente significan lo mismo?
Estas oraciones solo comparten una palabra, sin embargo, se consideran un 96% similares, porque básicamente significan lo mismo.
Si pasamos dos oraciones no relacionadas:
Como se esperaba, ligeramente por encima del 70%, pero si agregamos algún tipo de conexión entre las dos oraciones:
La similitud de coseno encuentra una relación más fuerte entre las últimas dos oraciones debido a la conexión con Estados Unidos.
También, cabe señalar que, dependiendo del modelo, la vectorización semántica de texto aún funciona en idiomas diferentes:
Algunos modelos funcionan mejor que otros en su soporte de diferentes idiomas, estos se hicieron usando el modelo text-embedding-ada-002 de OpenAI.
Buscando contenido similar
Excelente, ahora sabemos cómo hacerle una pregunta a ChatGPT, también sabemos cómo crear incrustaciones vectoriales de texto, y ahora entendemos cómo esos vectores pueden usarse con principios matemáticos para comparar su similitud. Ahora nos adentraremos en el proceso de búsqueda de contenido similar. El proceso es simple, pero consideremos una cosa más. Crear incrustaciones para una larga lista de documentos es costoso en tiempo y dinero, por lo que deberíamos encontrar una manera de crearlas solo una vez, o al menos solo tan a menudo como el contenido cambie. Dicho esto, el proceso debería ser bastante simple:
Preparación
- Recorrer la lista de todos tus documentos
- Obtener una incrustación para cada documento
- Guardar la incrustación junto con un puntero al documento correspondiente
- Persistir esta lista (en una base de datos vectorial, o en un dataframe de Pandas persistido)
En cada pregunta
- Obtener una incrustación para la pregunta
- Recorrer la lista guardada de incrustaciones/documentos
- Comparar la incrustación del documento con la incrustación de la pregunta
- Guardar la puntuación de comparación con el documento
- Ahora, tomar todos los documentos y filtrarlos basándose en algún umbral (>75% por ejemplo)
- Ordenar los que coincidan por la puntuación
- Elegir el primero… y el documento probablemente contenga una respuesta a tu pregunta
Para este ejercicio no usaré una base de datos vectorial, aunque definitivamente es el camino a seguir para una implementación en producción, en su lugar, simplemente tomaré el camino fácil y usaré un dataframe de pandas.
Vamos a añadir pandas y numpy a nuestro archivo:
import pandas as pdY vamos a añadir
Así que, ahora tenemos un Dataframe con una columna: textos. Ahora moveremos la creación de las incrustaciones a una función que podamos llamar repetidamente. Esto es clave en este punto, ya que vamos a añadir una nueva columna al dataframe llamada “embedding” que almacenará el resultado de llamar a la función get_embedding para cada texto.
Como puedes ver, cada fila en el dataframe ahora tiene el vector que representa el texto. Ahora, necesitamos obtener una incrustación para la pregunta:
question = "Is Peter a musician?"
question_embedding = get_embedding(question)Y luego añadir una nueva columna al dataset para almacenar la similitud entre el vector del texto y el vector de la pregunta.
Genial, así que ahora nuestro dataframe consiste en filas con el texto original, el vector del texto y la similitud con el vector de la pregunta. Probablemente podríamos simplemente revisar la lista y elegir la línea más cercana, pero intentemos hacerlo en código a ver si nos da una respuesta razonable.
El siguiente paso es usualmente filtrar la lista para que para los siguientes pasos tratemos con un subconjunto más pequeño. Hacemos esto filtrando el dataframe por una similitud mayor a cierto umbral, en este caso elegimos el 80%.
Ya vemos que la lista se redujo, solo 5 filas cumplen con los criterios. El siguiente paso es ordenar las filas filtradas en orden de similitud y elegir la coincidencia superior:
¡Excelente, usando las incrustaciones de OpenAI, hemos encontrado la respuesta a nuestra pregunta en la lista de documentos sin otra herramienta que puras matemáticas!
Finalmente, pediremos a ChatGPT que responda una pregunta basada en nuestro Contexto (RAG)
Ahora tenemos todos los elementos que necesitamos para finalmente hacer que ChatGPT use nuestro contexto para responder la pregunta. Al inspeccionar la afirmación que la matemática ayudó a seleccionar, probablemente ya podemos adivinar la respuesta. Pero, en casos del mundo real, este podría ser un documento muy largo, además, “Pedro toca el clarinete” no es una respuesta directa a la pregunta. Para eso utilizaremos el Modelo de Lenguaje Grande ChatGPT que no solo es capaz de entender la pregunta y el contexto, sino también de generar una respuesta apropiada.
Y ahora, el momento de la verdad, obtendremos el valor de la respuesta más acertada que encontramos coincidiendo con la pregunta y lo pasaremos a la llamada de chat como contexto:
Eso es lo que RAG significa realmente. Aumentar el contexto para que ChatGPT pueda responder una pregunta recuperando información utilizando datos vectorizados.
Ahora, por supuesto, hay mucho más para crear una aplicación a nivel de producción utilizando estas tecnologías. Los modelos de incrustación más nuevos crean vectores más grandes (mayor precisión, pero búsqueda más lenta), pero también permiten acortarlos, lo que se puede usar para hacer una búsqueda en dos pasos filtrando el conjunto total de documentos con un vector menos granular y luego usando el vector de mayor dimensión para el conjunto más pequeño. Solo he usado textos cortos aquí, pero los mismos principios funcionan para documentos más grandes. Los documentos necesitarán algún procesamiento, como abrirlos (extraer texto de PDFs, etc.), fragmentar (dividir los documentos en unidades más pequeñas, potencialmente superponiendo los fragmentos para evitar cortar el flujo), usar una base de datos vectorial, implementar búsquedas híbridas (palabras clave, semántica, etc.).
Así que, sí, hay mucho otro trabajo por hacer para llevar esta aplicación a producción, pero espero que si has leído hasta aquí, tengas un mayor entendimiento de cómo funciona RAG.