

Read in English
Y si, es complejo
Lambda, Azure Functions, OpenFaaS, Kubeless, Knative, incluso Deno deploy, y la lista podría continuar, sí, las probé y soy un poco escéptico con respecto a los beneficios que brindan a un desarrollador que ya puede desplegar una aplicación usando kubernetes en 5 minutos o menos. Sin embargo, aquí estoy, escribiendo sobre por qué no debería ser solo una opción para el desarrollo de software, sino una necesidad para las empresas.
¿La vida de quién estás tratando de mejorar?
La decisión de servidores o serverless no debe basarse en cuán compleja es la configuración bajo la línea de flotación [1], sino en cuánto simplifica el punto de entrada para los usuarios reales. No hay nada de malo en gastar esfuerzos en automatizar tus tareas diarias y simplificar tus obligaciones, pero esos esfuerzos tienen que traducirse eventualmente en un mejor/más simple/más rápido servicio al cliente, o no habrás logrado mucho. Desde una perspectiva de IT (Tecnología de Información por sus siglas en Inglés), nuestro objetivo no es mejorar nuestras vidas (aunque debemos ser lo suficientemente inteligentes como para lograrlo al mismo tiempo), sino brindar una experiencia mejor/más simple/más rápida a nuestros usuarios.
Consideremos el siguiente cuadro:
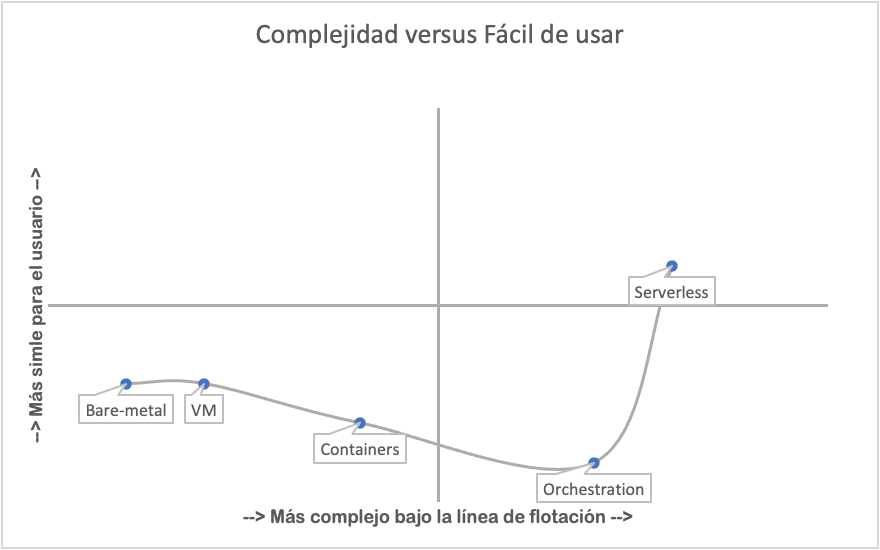
La única tecnología que aparece en la mitad superior del gráfico es serverless, desafortunadamente, también está en la mitad derecha, lo que significa que, para las personas que la respaldan como plataforma, es bastante más compleja que las ofertas anteriores.
¿Quién es tu cliente?
Pero, antes de continuar, estoy seguro de que la mayoría de los desarrolladores mirarán el gráfico anterior y pensarán que está totalmente equivocado porque, según su experiencia, los contenedores y la orquestación han facilitado su trabajo, por lo que deben colocarse en una línea ascendente, o algo así como el siguiente gráfico:
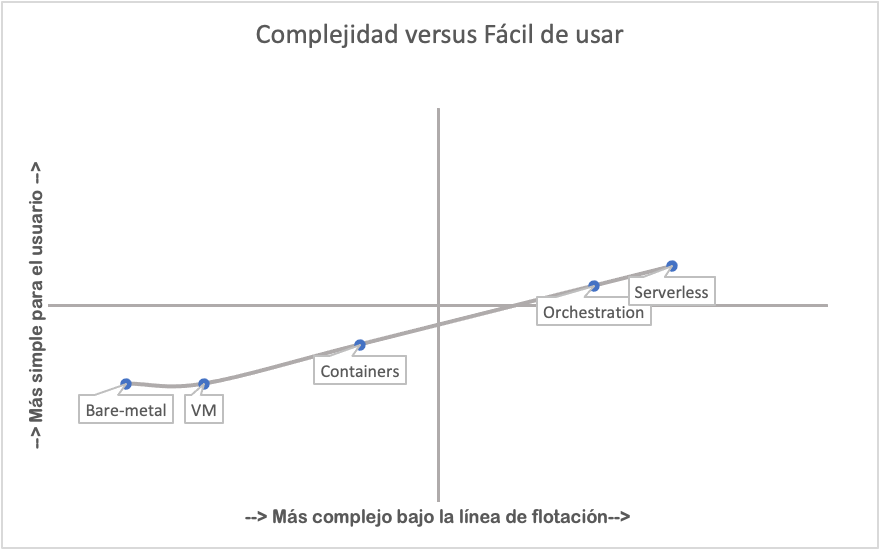
Y estarían en lo correcto, desde su perspectiva, pero es solo porque están agregando otra dimensión al problema. Los desarrolladores no solo están considerando la experiencia necesaria para crear contenedores o describir su orquestación, sino que también evalúan todos los procesos necesarios para que sus aplicaciones funcionen en un entorno no orquestado. La siguiente tabla obviamente está simplificada, pero ilustra la percepción de que al usar contenedores y orquestación, habrá mucho menos trabajo que usando máquinas virtuales o reales.
| Actividades requeridas | Bare-metal/VM | Contenedores | Orquestación | Serverless |
| Lógica de la aplicación | x | x | x | x |
| Solicitud inicial | x | x | x | |
| Firewalls/network | x | x | ||
| Certificados | x | x | ||
| Parches del Sistema Operativo | x |
Pero, lo que esa percepción no tiene en cuenta es que una persona cuyo trabajo es desarrollar aplicaciones considera que aprender sobre contenedores y orquestación es una tarea trivial, una herramienta necesaria y muy útil en su conjunto de herramientas para crear aplicaciones más rápido. Y ese conocimiento es muy valioso para ella porque cada aspecto de la aplicación ahora está bajo su control.
Pero, esta programadora puede que no sea tu única cliente, y diría que, en un futuro corto, no será tu cliente más importante.
Los científicos de datos de hoy son expertos en usar python para sus proyectos de investigación. Una vez que se ha creado la lógica, el investigador desea ejecutarla en un entorno que asegure estabilidad y escalabilidad. Si el investigador fuera a implementar la función en un clúster de kubernetes, por ejemplo, necesitaría aprender sobre contenedores, rutas, firewalls, etc., todo lo cual agrega cero valor a su objetivo de ejecutar el código en un entorno más estable y escalable. Sí, él es lo suficientemente inteligente como para aprender, e incluso podría estar dispuesto a hacerlo, pero, ¿es realmente el mejor uso de su tiempo y esfuerzo? Muy bien podría ser que este usuario, y la los equivalentes SME[2]en medicina, arquitectura, etc., pronto sean clientes tan, o más, importantes para los servicios de IT como el programador a tiempo completo que escribe aplicaciones en la actualidad. Y, para este usuario SME, el bagaje heredado de la “aplicación” es solo un peso extra. Consideremos serverless.
Serverless
Como probablemente ya hayas escuchado, serverless no significa que no haya servidores, solo que no tendrás que lidiar con ellos. Probablemente haya más servidores involucrados en una configuración serverless que en una implementación tradicional de kubernetes. Serverless no está destinado a reemplazar a las aplicaciones (o la funcionalidad basada en servidor), todavía hay muchos escenarios de uso para las aplicaciones y es importante evaluar cuidadosamente los requisitos para determinar qué solución los satisface mejor.
Serverless bajo las cubiertas es muy parecido a kubernetes, y la mayoría de las ofertas más nuevas en realidad se ejecutan sobre kubernetes. ¿Entonces cuál es la diferencia? Básicamente dos:
- Serverless proporciona un nivel de abstracción encima de kubernetes permitiendo que el usuario se concentre en la funcionalidad y no en la infraestructura; en kubernetes, independientemente de la tecnología utilizada para implementar la aplicación, el desarrollador aún tenía que definir servidores, servicios, redes, almacenamiento, etc., mientras que en serverless el desarrollador es libre de concentrarse en su funcionalidad.
- Serverless proporciona el concepto de spin-to-zero. En kubernetes, una aplicación está activa (tiene contenedores, pods, rutas, etc. ejecutándose en su clúster) o no lo está (no se está ejecutando nada y su aplicación no puede responder a ningún evento). Se puede iniciar más pods para hacer que la aplicación escale, pero no se puede reducir a menos de uno (lo que significa que pagará por todos esos recursos incluso mientras no se estén utilizando). Con serverless, usted registra sus funciones/aplicaciones con el sistema serverless y define qué gatillos desencadenarán sus ciclos de vida, pero hasta que ocurra ese evento (tráfico entrante, calendario, etc.), no se asignan recursos (lo que podría significar menos dinero), y tan pronto se haya tramitado el evento, los recursos se vuelven a reducir a cero.
Hay diferentes tipos de soluciones en el espectro serverless:
- Backend como servicio (BaaS por sus siglas en Inglés): proporciona todos los servicios que necesitará una aplicación web o móvil (MBaaS) en el backend sin tener que administrar servidores. Estos servicios sin servidor podrían incluir cosas como bases de datos escalables, autenticación, etc.
- Contenedor como servicio (CaaS por sus siglas en Inglés): permite que la empresa ejecute funciones o aplicaciones basadas en contenedores sin preocuparse por la infraestructura que se encuentra debajo. El principal jugador de código abierto en el momento de escribir este artículo es claramente Knative, aunque algunos argumentarán que Knative también se puede utilizar como una plataforma FaaS.
- Función como servicio (FaaS por sus siglas en Inglés): permite la ejecución de piezas únicas de lógica sin tener en cuenta la infraestructura. Los nombres principales aquí son AWS Lambda, Google Functions, Azure Functions y entre las de código abierto, OpenFaaS.
Si bien es cierto CaaS probablemente continuará avanzando como la forma en que las empresas despliegan funcionalidad, la adopción inicial probablemente será principalmente entre los desarrolladores profesionales de aplicaciones. Teniendo en cuenta que considero que los SMEs se están convirtiendo en consumidores muy importantes de plataformas de IT, concentraré el resto de este artículo en la función como servicio (FaaS).
Escenarios de uso
Implementación de un API de contenido estático
Esta debería ser una opción fácil, si necesita implementar una API para acceder o actualizar contenido estático, serverless es el camino a seguir. En esta configuración, no tendrá que preocuparse en absoluto por la infraestructura subyacente, simplemente defines la interfaz y la funcionalidad y la publicas en un entorno serverless.
ETL de datos
Los ETL de datos (Extracción, Transformación y Carga – ETL por sus siglas en Inglés) son candidatos perfectos para la tecnología sin servidor. Los ETL se utilizan para mover grandes cantidades de datos de forma asincrónica, generalmente calendarizado, aunque también pueden desencadenarse por cambios en los datos, los ETL generalmente no son sensibles a la latencia.
En general, serverless es extremadamente útil para funciones asincrónicas puras[3] y sin estado[4]. Entonces, miremos un poco más detalladamente a FaaS.
FaaS – Abstracción de un nivel superior, la función
El primer desafío de serverless es degradar el concepto de “aplicaciones” [5] con todos los componentes que estas requieren y elevar el concepto de la función que quiere proporcionarse. Ahora, serverless no necesariamente es igual a FaaS, pero comparten la mayoría de los mismos conceptos. Mientras que la implementación de AWS Lambda y Deno deploy son FaaS porque permiten que el desarrollador se concentre solo en la función que desea publicar, son únicos en el sentido de que son propietarios y no se ejecutan sobre kubernetes. La mayoría de las otras opciones de FaaS brindan la libertad de elegir el lenguaje de desarrollo, pero resuelven los problemas de dependencia de manera diferente.
Tabla de lenguajes
| AWS Lambda | Google Functions | Azure Functions | OpenFaaS | Deno deploy | |
| Javascript | x | x | x | x | x |
| Go | x | x | x | ||
| Python | x | x | x | x | |
| Java | x | x | x |
Código abierto/propietario
La mayoría de los proveedores de la nube tienen una solución serverless FaaS, por ejemplo, AWS Lambda, Google Functions, Azure Functions, IBM Cloud Functions y Alibaba Functions. Todas ellas son soluciones muy potentes pero propietarias y no portátiles. También existen las ofertas de código abierto DIY (“Házlo tú mismo” por sus siglas en Inglés) que se pueden usar localmente o en cualquier proveedor de la nube: OpenFaas, Fn, Kubeless y OpenWhisk.
Conclusión
Serverless no es una tecnología futura. Sí, seguirá evolucionando, pero es totalmente real, y si no ha estado justo en medio de tu estrategia de innovación como centro de la expansión de la base de usuarios para soluciones altamente técnicas, ya estás tarde.
[1] : Línea de flotación es un término que hemos estado usando para separar lo que el usuario/cliente puede ver e interactuar de lo que el proveedor de servicios necesita hacer para que el entorne funcione para el cliente. Si su servicio es proporcionar máquinas virtuales para que los clientes ejecuten sus aplicaciones, su línea de flotación es el sistema operativo, el cliente no sabe/ni le importa el metal, pero si proporciona un clúster de kubernetes, entonces la línea de flotación es el plano de control k8s, y el cliente no sabe/ni le importan las máquinas virtuales sobre las que corre el clúster.
[2] : SME, un experto en la materia es una persona con un conocimiento profundo de un dominio específico. En este artículo, utilizo el término para identificar a alguien que es un experto en un campo DISTINTO al desarrollo de aplicaciones.
[3] : Funciones puras – Según programación funcional una función pura es aquella que, dada la misma entrada, debería devolver la misma salida sin efectos secundarios. Por ejemplo, si mi función es una función de suma, siempre debería devolver exactamente el mismo resultado dados los mismos parámetros de entrada (2+3=5, todas las veces, independientemente de la hora del día). No todas las funciones necesitan ser puras, por ejemplo, getNextId() no es un buen candidato para una función pura, tampoco lo es la función rand(), por razones obvias. Pero hay muchas funciones que deberían ser puras y están mal implementadas como impuras. Por ejemplo, isSignatureValid(object) se vuelve innecesariamente impura, porque la función dependerá de una autoridad externa fuera del control de la persona que llama. FP dicta que una función más legible y comprobable debería ser isSignatureValid (objeto, autoridad). La parte “sin efectos secundarios” significa que una función pura no modifica ninguna variable externa (incluidas las variables de entrada) excepto la salida.
[4] : La función sin estado significa que la función no puede guardar el estado dentro de la función en sí, en otras palabras, las funciones sin servidor son de corta duración y el estado no se conserva para la próxima ejecución. Si bien las funciones sin servidor son capaces de conectarse a bases de datos y/o recuperar y preservar el estado externamente, hacerlo podría convertirse en un antipatrón de principios de programación funcional. Debe agregarse que algunos proveedores como Microsoft Azure tienen una funcionalidad de estado diseñada para sus funciones sin servidor y la anuncian como una característica positiva (Durable Functions).
[5] : Originalmente, las aplicaciones eran piezas de software que se instalaban encima de un sistema operativo, que brindaban funcionalidad a un usuario, generalmente a través de una interfaz gráfica de usuario (GUI). Durante la revolución DevOps, las piezas de software que se implementaron, incluso si no tenían una GUI, se incluyeron en el concepto. Por ejemplo, la implementación de una API que nunca está destinada a la interacción directa con un usuario final, comenzó a considerarse una aplicación.