

Leer en Español
Yes, it is complex
Lambda, Azure Functions, OpenFaas, Kubeless, Knative, even Deno deploy, and the list could go on, yes, I have tried them and I am a little skeptical with what benefits they provide to a developer that can already spin up an application on kubernetes in 5 minutes or less. Yet, here I am, writing about why it shouldn’t be just an option for software development, but a must for enterprises.
Who’s life are you trying to improve?
The decision of server-based or serverless should not be based on how complex the setup is under the waterline [1], but how much does it simplify the entry point for the actual users. There is nothing wrong with spending efforts automating your daily tasks and simplifying your obligations, but, those efforts have to eventually translate into a better/simpler/faster customer service, or you haven’t accomplished much. From an IT perspective, our goal is not to improve our lives (although, we should be smart enough to accomplish it as we go), but to provide a better/simpler/faster experience to our users.
Let’s consider the following chart:
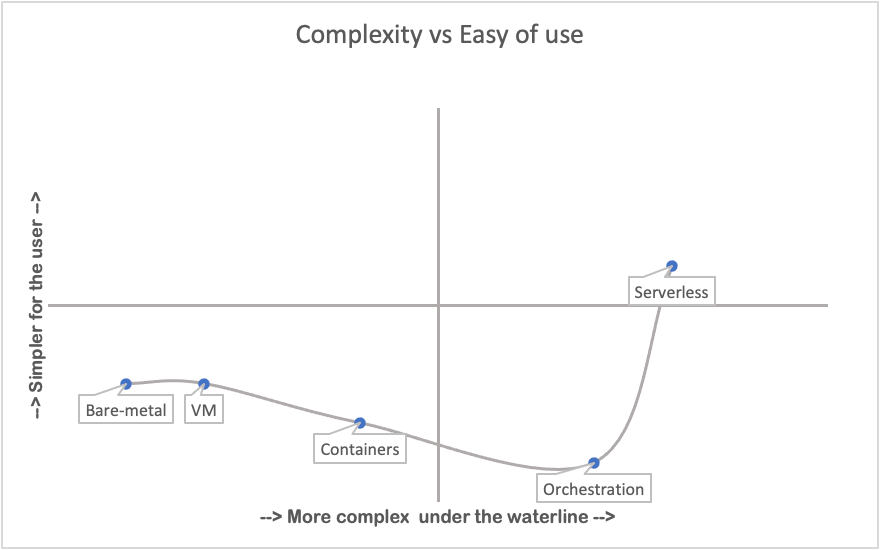
The only technology that appears on the upper half of the chart is serverless, unfortunately, it is also on the right half, which means that, for the people supporting it as a platform, it is much more complex than the previous offerings.
Who is your customer?
But, before I continue, I am sure most developers will look at the previous chart and think that it is totally wrong because, in their experience, containers and orchestration have made their jobs easier so they should be placed on an ascending line, or something closer to the following chart:

And, they would be correct, from their perspective, but it is just because they are adding another dimension to the issue. Developers are not just looking at the expertise it takes to build containers or describe their orchestration, they are weighing in all the processes that were required to make their applications work in a non-orchestrated environment. The following table is obviously simplified but illustrates the perception that by using containers and orchestration you will be doing a lot less work than bare-metal and VMs.
| Required activities | Bare-metal/VMs | Containers | Orchestration | Serverless |
| Application logic | x | x | x | x |
| Initial Request | x | x | x | |
| Firewalls/routes | x | x | ||
| Certificates | x | x | ||
| OS patching | x |
But, what that perception doesn’t take into account is that a person whose job is to develop applications considers learning about containers and orchestration a trivial task, a necessary and very useful tool in her toolset to create applications faster. And, that knowledge is very valuable to her because every aspect of the application is now under her control.
But, this developer may not be your only customer, and I would argue that, in the short future, she won’t be your most important customer.
Data scientists nowadays are experts in using python for their research projects. Once the logic has been created, the researcher wants to run it in an environment that assures stability and scalability. If the researcher was to deploy the function to a kubernetes cluster, for example, he would need to learn about containerization, routes, firewalls, etc., all of which add zero value to his goal of executing the code in a more stable and scalable environment. Yes, he is smart enough to learn, and might be even willing to do it, but, is it really the best use of his time and effort? It very well could be that this user, and the equivalent SME [2] in medicine, architecture, etc., will soon be as, or more, important a customer to the IT services as the full time developer who writes applications today. And, to this SME user, the legacy “application” baggage is just extra weight. Enter serverless.
Serverless
As you have probably already heard, serverless does not mean that there are no servers, just that you won’t have to deal with them. There are probably more servers involved in a serverless setup than in a traditional kubernetes deployment. Serverless is not meant to replace applications (or server-based functionality), there are still plenty of use cases for applications and it is important to evaluate carefully the requirements to determine which solution better satisfies them.
Serverless under the covers is very much like kubernetes, and most of the newer offerings actually run on top of kubernetes. So, what is the difference? Basically two:
- Serverless provides a level of abstraction on top of kubernetes to allow the user to concentrate on the functionality and not the infrastructure; in plain kubernetes, regardless of the technology used to deploy the application, the developer still had to define servers, services, networks, storage, etc., where in serverless the developer is free to concentrate on their functionality.
- Serverless provides the concept of spin-to-zero. In plain kubernetes an application is either live (you have containers, pods, routes, etc. running in your cluster) or it is not (nothing is running and your application cannot respond to any events). More pods could be spun to make your application scale, but you cannot spin down lower than one (which means you will be paying for all those resources even while they are not being used). With serverless, you register your functions/applications with the serverless sytem and define what would trigger their lifecycles, but until that event happens (incoming traffic, schedule, etc.), no resources are allocated (which could mean less money), and soon after the event is handled, the resoucers are spun down back to zero.
There are different flavors of solutions in the serverless spectrum:
- Backend-as-a-Service (BaaS) – Provide all the services that a web or mobile (MBaaS) app will need in the backend without having to manage servers. These serverless services could include things like scalable databases, authentication, etc.
- Container-as-a-Service (CaaS) – Enable the enterprise to run container based functionality or applications without concern for the infrastructure under it. The main open-source player at the time of this writing is clearly Knative, although some will argue that Knative can also be used as a FaaS platform.
- Function-as-a-Service (FaaS) – Enable the execution of single pieces of logic without regard to the infrastructure. The main names here are AWS Lambda, Google Functions, Azure Functions, and the open-source OpenFaaS.
While CaaS will probably continue to make inroads in the way enterprises deploy functionality, the initial adoption will probably be mostly by the professional application developer. Having in mind that I consider that SMEs are becoming very important consumers of IT platforms, I will concentrate the rest of this article on Function-as-a-Service.
Use Cases
API implementation of static content
This one should be an easy choice, if you need to implement an API to access or update static content, serverless is your way to go. In this setup, you won’t have to worry about the underlying infrastructure at all, just define the interface and the functionality and publish it to a serverless environment.
Data ETLs
Data ETLs (Extract, Transform, and Load) are perfect candidates for serverless. ETLs are used to move large amounts of data asynchronously, usually on a scheduled basis, and even though they could also be triggered by changes in data, ETLs are usually latency insensitive.
In general, serverless is extremely helpful for stateless [3], pure[4] asynchronous functions. So, let’s have a little more detailed view of FaaS.
FaaS – Abstraction of a higher level, the function
The first challenge of serverless is to demote the concept of “applications”[5] with all the components that they require and elevate the concept of the function that needs to be provided. Now, serverless does not necessarily equal FaaS, but they share most of the same concepts. Whereas AWS Lambda and Deno deploy are FaaS because they allow the developer to just concentrate on the function they want to publish, they are somewhat unique in that they are proprietary and do not run on top of kubernetes. Most of the other FaaS options provide the freedom to pick the development language but solve dependencies issues differently.
Language support
| AWS Lambda | Google Functions | Azure Functions | OpenFaaS | Deno deploy | |
| Javascript | x | x | x | x | x |
| Go | x | x | x | ||
| Python | x | x | x | x | |
| Java | x | x | x |
Open-source/Propietary
Most of the cloud providers have a serverless FaaS solution, namely, AWS Lambda, Google Functions, Azure Functions, IBM Cloud Functions, and Alibaba Functions. All of them are very powerful but proprietary, non-portable solutions. You also have the DIY open-source offerings that can be installed on-prem or on any cloud provider: OpenFaas, Fn, Kubeless and OpenWhisk.
Conclusion
Serverless is not a future technology. Yes, it will continue to evolve, but it is as real as it can be, and if it has not been right in the middle of your innovation strategy as the basis of the expansion of the user base for highly technical solutions, you are already late.
[1]: Waterline is a term that we have been using to separate what the user/customer can see and interface with from what the service provider needs to keep running for the customer. If you are providing VMs for customers to run their applications, their waterline is the OS, they don’t know/don’t care about the metal, but if you are providing a kubernetes cluster, then the waterline is the k8s control plane, and they don’t know/don’t care about the VMs that the provider is running the cluster on.
[2]: SME, a Subject Matter Expert is an individual with deep knowledge of a specific domain. In this article, I use the term to identify someone who is an expert on a field OTHER THAN application development.
[3]: Stateless function means that the function is incapable of saving state within the function itself, in other words, serverless functions are short-lived and the state is not preserved for the next run. While serverless functions are capable of connecting to databases and/or retrieve and preserve state externally, doing so might become an anti-pattern of functional programming principles. It should be added that some providers like Microsoft’s Azure have architected state functionality for their serverless functions and advertise it as a feature (Durable functions).
[4]: Pure functions – According to functional programming a pure function is one that given the same input should return the same output with no side effects. For example, if my function is a sum function it should always return the same exact result given the same input parameters (2+3=5, every time regardless of the time of the day). Not all functions need to be pure, for example, getNextId() is not a good candidate for a pure function, neither is the rand() function, for obvious reasons. But there are many functions that should be pure and are wrongly implemented as impure. For example, isSignatureValid(object) is unnecessarily made impure, because the function will depend on an external authority outside of the control of the caller. FP dictates that a more readable, reusable and testable function should be isSignatureValid(object,authority). The “no side effects” part means that a pure function does not modify any external variable (including the input variables) except for the output.
[5]: Originally, applications were pieces of software that you installed on top of an Operating System, that provided functionality to a user, typically through a Graphical User Interface (GUI). During the DevOps revolution, pieces of software that were deployed, even if they didn’t have a GUI, were included in the concept. For example, the implementation of an API that is never intended for direct interaction with an end user, started being considered an application.